The Internet is a fortune trove of adapting, especially for understudies searching for provoke information charm. Regardless, the ‘Net contains billions of records, and with the exception of on the off chance that you know the right URL of the one you require, you should rely upon web crawlers to empower you to reveal the data you require. Look at the hidden wiki for some astounding realities. Web crawlers are gadgets that empower you to examine for information access on the Web using catchphrases and chase terms. Rather than glancing through the Web itself, in any case, you are extremely glancing through the engine’s database of reports. Web crawlers are extremely three separate instruments in one. The creepy crawly is a program that “crawls” through the Web, moving from association with the interface, looking for new site pages. When it finds new goals or archives, they are added to the web crawler’s record. This record is an open database of the considerable number of information that the dreadful little creature has found on the Web. A couple of engines document each word in each record, while others select certain words. The web crawler itself is a touch of programming that empowers customers to glance through the engine’s database. Undeniably, an engine’s interest is simply on a standard with the record it’s looking.
Step by step instructions to utilize these device
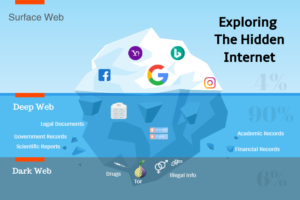
When you run a request using a web seek device, you’re incredibly simply glancing through the engine’s record of what’s on the Web, rather than the entire Web. No one important web crawler is fit for requesting everything on the Web – there’s essentially an abundance of information out there! Moreover, various bugs can’t or won’t enter databases or record archives. Along these lines, a noteworthy piece of the information kept away from in web list questions joins breaking news, chronicles, media records, pictures, tables, and other data. Everything considered, these sorts of benefits are implied as the significant or imperceptible Web. They’re canvassed some place down in the Web and are imperceptible to web files. While many web crawlers feature a couple of districts of the significant web, by far most of these advantages require remarkable devices to reveal them. Assessments change be that as it may, the significant web is much greater than the surface web. Approximately 500 extra events information is arranged on the significant web as exists externally web. This contains sight and sound archives, including sound, video, and pictures; programming; reports; continuously evolving substance, for instance, breaking news and occupation postings; and information that is secured on databases, for example, phone catalog records, real information, and business data. Obviously, the significant web has something to offer for all intents and purposes any understudy master. The clearest way to deal with find information on the significant web is to use a specific web record. Many web look apparatuses document a little piece of the significant web; nevertheless, a couple of engines center around the significant web unequivocally. If you need to find a bit of information that is presumably going to be named some bit of the significant web, web crawlers that accentuation on such substance is your most consistent alternative. Like surface web engines, significant web crawlers may moreover move to expose as paid postings. The difference in their consideration of significant web substance and offer one of a kind impelled look for options. Engines that glance through the significant web can be appointed first versus the second time, solitary versus meta, or conceivably separate versus assembled recuperation, comparably similarly with surface web engines.